
Озираючись на результати ряду досліджень, проведених за 13 років, ми бачимо, що основні принципи сканування людиною тексту залишаються незмінними навіть при зміні дизайну.
Чим більше речі змінюються, тим більше вони залишаються незмінними.
Нещодавно ми опублікували 2-е видання нашого юзібіліті дослідження «Як люди читають онлайн», через майже 15 років після публікації 1-го етапу. Озираючись назад на результати 5-ти досліджень, проведених для цих видань, ми можемо простежити, як змінилося чи ні поведінку при читанні в Інтернеті.
Ми говоримо про це з 1997 року:
Люди рідко читають в Інтернеті - вони набагато частіше сканують, ніж читають слово в слово.
Це одна з фундаментальних істин поведінки, пов'язаного з пошуком інформації в Інтернеті. Воно не змінилося за 23 роки і має суттєвий вплив на те, як ми створюємо цифровий контент.
Причина, по якій цей висновок і інші, обговорювані тут, все ще вірні, полягає в тому, що він заснований на базовому поведінці людини.
Незважаючи на те, що масові зміни в технологіях змінили деякі моделі поведінки, багато хто з наших первинних висновків про те, як люди читають онлайн, Залишаються вірними навіть після 20 з гаком років.
Содержание | Быстрая навигация
Методологія: Eyetracking.
Устаткування Eyetracking відстежує погляд користувача, коли він використовує інтерфейс.
Цей тип дослідження корисний для багатьох цілей, включаючи оцінку візуального дизайну. Особливо він потрібен для вивчення того, що люди читають або не читають в Інтернеті.
Більшість досліджень, обговорюваних нижче, містили як кількісну, так і якісну частину.
У кількісних дослідженнях, присвячених відстеження подій, агрегується поведінку при перегляді у великого числа учасників. Результати включають теплові карти і метрики погляду. Наприклад, середня кількість фіксацій на конкретному елементі, що представляє інтерес для інтерфейсу.
У якісних дослідженнях відстеження зору дослідники аналізують поведінку користувачів при перегляді за допомогою gazeplots і повторів погляду. У багатьох випадках ми просили учасників принести свої власні завдання для роботи, навчання або особистому житті для виконання в цій частині сеансу.
Результати цього другого видання звіту отримані в результаті серії досліджень, що охоплюють 13 років. У них взяли участь понад 500 учасників і понад 750 годин часу на відстеження.
Ранні юзабіліті дослідження 2006-2013 рр.
У 2006 році ми провели масштабне дослідження, присвячене відстеження, щоб зрозуміти, як люди читають онлайн. У ньому взяли участь понад 300 учасників. Результати вивчення 2006 року лягли в основу першого видання нашого доповіді «Як люди читають в Інтернеті».
Пізніше ми провели два невеликих якісних дослідження в 2009 і 2013 роках, щоб отримати нові висновки і приклади для поновлення звіту. Вони не привели до всеосяжним змін або до нової редакції звіту.
Останні юзабіліті дослідження 2016-2019 рр.
З 2016 та 2017 років роках ми провели 2 кількісних дослідження відстеження рухів очей в двох різних місцях в Сполучених Штатах:
- Ролі, Північна Кароліна - 46 учасників,
- Сан-Франциско, Каліфорнія - 105 учасників.
Ці дослідження були спрямовані на вивчення того, як люди читають онлайн. Дані стали в нагоді і для інших дослідницьких цілей. Наприклад, вплив інтерфейсів з низьким рівнем значущості на дизайн взаємодії.
У 2019 ми провели великомасштабне дослідження, присвячене відстеження подій. Воно призначене спеціально для збору результатів для другого видання звіту «Як люди читають онлайн». Дослідження проводилося в двох місцях:
- Ролі, штат Північна Кароліна, США - 48 учасників,
- Пекін, Китай - 12 учасників.
Ми знаходимо, що моделі поведінки, в тому числі шаблони читання, дуже схожі в різних мовах і культурах, тому що вони засновані на людській поведінці.
Коли ми зустрічаємо культурні відмінності, вони часто присутні при порівнянні американської або європейської культури з азіатськими культурами. Якісна частина дослідження, проведеного в Пекіні, була спрямована на виявлення будь-яких культурних відмінностей в обробці контенту, якщо вони існували.
Що змінилося?
Нові макети, новий шаблон.
З 2006 року способи подання мови змінилися. Адаптивний дизайн означає, що контент може відображатися гнучко в залежності від ширини вікна або розміру пристрою. Як наслідок, деякі поради, які ми дали в 2006 році, більше не застосовуються.
Наприклад, 1-е видання рекомендувало людям використовувати «рідкий макет» замість «фіксованого макета» для тексту. Хоча ця рекомендація була корисна в той час, зростання адаптивного дизайну настільки популяризував цей підхід, що нам більше не потрібно його рекомендувати.
Крім того, зростання популярності таблиць порівняння і звивистих макетів, де текст і зображення чергуються в кожному рядку на сторінці, збігся з розробкою нового шаблону погляду.
На сторінках з різними осередками вмісту люди часто обробляють їх у вигляді газонокосарки. Вони починають читання у верхній лівій клітинці, переміщаються вправо до кінця ряду, потім опускаються до наступного ряду, переміщаються вліво до кінця рядка, опускаються на наступний ряд і т. Д.
Назва цієї моделі натхненне тим, як газонокосарка методично переміщається вперед і назад по полю трави. Газонокосарка переміщається з одного боку газону на іншу, потім перевертається і косить наступний ряд трави в протилежному напрямку.

Ця сторінка є приблизною ілюстрацією схеми газонокосарки. Стрілки показують, як рухаються очі. В цьому випадку погляд переміщається по рядку в таблиці справа наліво, потім вниз до наступного рядка і переміщається вліво.

Один учасник відсканував цю сторінку опису продукту для Apple Watch 3, зліва, яка мала зигзагоподібний макет. Його рухи очей показані в газеплоте, праворуч. Вони переходили від зображення до тексту, до зображення, до тексту за принципом руху газонокосарки.
Комплексні сторінки результатів пошуку.
Ми виявили, що користувачі сканують SERP набагато менш лінійно, ніж раніше. Це так ймовірно, через збільшення можливостей SERP в пошуковій видачі Google, а також конкурентів, таких як Bing.
Багаті, різноманітні макети сучасних SERP викликали розробку нового патерну: пінбол. У такій схемі користувач переглядає сторінку результатів по вкрай нелінійного шляху, перебираючи результати і функції SERP.

Ця ілюстрація є зображенням схеми пинбола, яка характеризується «стрибучими» поглядами між різними елементами SERP. Зазвичай рух відбувається між правою бічною панеллю і центральною колонкою результатів.

Один учасник шукав інформацію про ціни на Ботокс. Пронумерований газеплот показує всі його фіксації за 14 секунд, які сформували малюнок пинбола. І так, він переглянув 158 точок за 14 секунд. Ця швидкість сканування нормальна.
Крім зміни структури погляду, ці функції SERP також справили величезний вплив на поведінку пошуку інформації. Функції SERP можуть:
- Діяти як покажчики: їх зображення можуть допомогти користувачам швидко переконатися, що вони шукають передбачуваний об'єкт.
- Звернути увагу користувача: функції SERP мають великий візуальний вага на сторінці, що може відвернути погляд користувача в різних напрямках. Це головна причина паттерна пинбола.
- Врахувати запити і завдання. Деякі функції SERP, такі як елемент People і ask або карусель, дозволяють Google уявити кілька розширених інтерпретацій запиту і дозволяють користувачам досліджувати ці альтернативи, не залишаючи сторінки.
Забезпечте швидкі відповіді. Для простих інформаційних потреб функції SERP часто відповідають на запитання користувачів безпосередньо в самій SERP. Їм більше не потрібно натискати на результати пошуку для досягнення своїх цілей - явище, зване хорошим відмовою.
Моделі погляду в Китаї.
У 2006 році ми вивчали тільки англомовні сайти і користувачів, але припустили, що ми знайдемо ті ж шаблони читання і на інших мовах.
У нашому недавньому дослідженні користувачів в Пекіні ми виявили, що китайські користувачі продемонстрували також майже кожен шаблон і поведінку, яке ми виявили в американських користувачів.
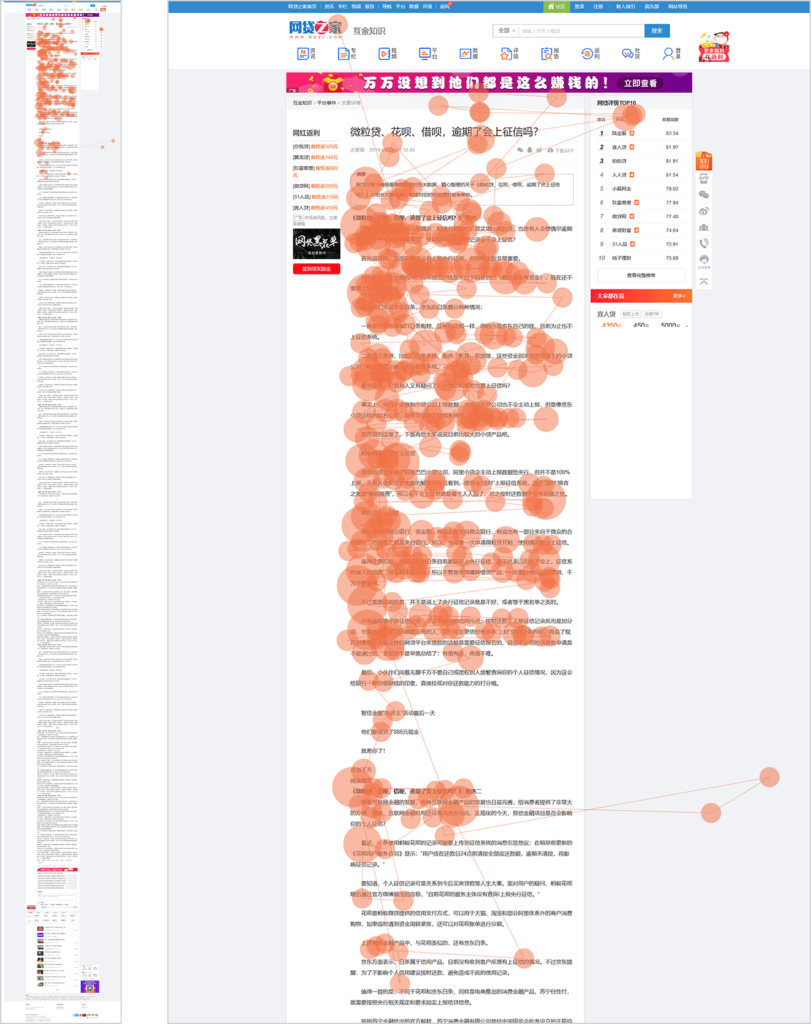
Один з учасників нашого пекінського дослідження відсканував цю надзвичайно довгу сторінку з WDZJ.com. Він сканував тільки першу п'яту частину повної сторінки, ліворуч, перш ніж покинути її. Його сканування сформувало класичний F-зразок, справа.
Єдиним винятком був малюнок пинбола; з більш ніж 60 випадків пошуку ми спостерігали тільки один випадок паттерна пинбола на Baidu SERP.
Ми припускаємо відсутність шаблонів пинбола, тому що Baidu забезпечує:
- Менше функцій SERP на запит, ніж Google.
- Функції SERP, які не такі привабливі візуально, як функції SERP від Google, менше і менше зображень.
- Елементи бічній панелі, що містять рекламу і посилання на інші видачі в меншій мірі пов'язані з поточним запитом користувача, ніж панель знань Google. Наприклад, пов'язані запити Baidu або елементи пошуку людей.
Існує як мінімум 3 основних відмінності між використанням Інтернету в США і Китаї:
- культура; набір символів, латинський алфавіт проти набагато більш багатою і щільною китайської системи письма;
- різні сайти і сервіси з різним дизайном, включаючи тенденцію до того, що китайські сайти мають більш високу складність дизайну, ніж західні.
Беручи до уваги ці відмінності, разюче, що поведінка користувачів при читанні в обох країнах було практично однаковим.
Хоча цей висновок не є доказом того, що інші країни будуть демонструвати таку ж поведінку, ми вважаємо, що це, ймовірно, так.
Наприклад, дослідження noneyetracking, які ми провели з арабськими сайтами, де читання справа наліво, виявили ту ж саму поведінку, але в дзеркальному відображенні.
Нові елементи контенту.
У порівнянні з 2006 роком популярність отримали 3 типи контенту:
- таблиці, включаючи порівняльні таблиці;
- вбудовані елементи, цитати і реклама;
- призначений для користувача контент відгуки і пости.

ScienceMag.com використовував повні лапки, як показано тут, а також вбудовані повідомлення про свою розсилці.
В результаті наше останнє дослідження виявило поведінку і переваги навколо цих елементів контенту.
Наприклад, хоча в нашому дослідженні фіксовані лапки і вбудовані повідомлення отримували фіксації, ми також помітили, що вони мають тенденцію порушувати читання.
Кілька учасників нашого дослідження почали читати статті майже лінійно і повністю, поки не потрапили в цитату або рекламне оголошення. Досягнувши одного з цих елементів, учасники відмовилися від читання і занурилися в легке сканування.
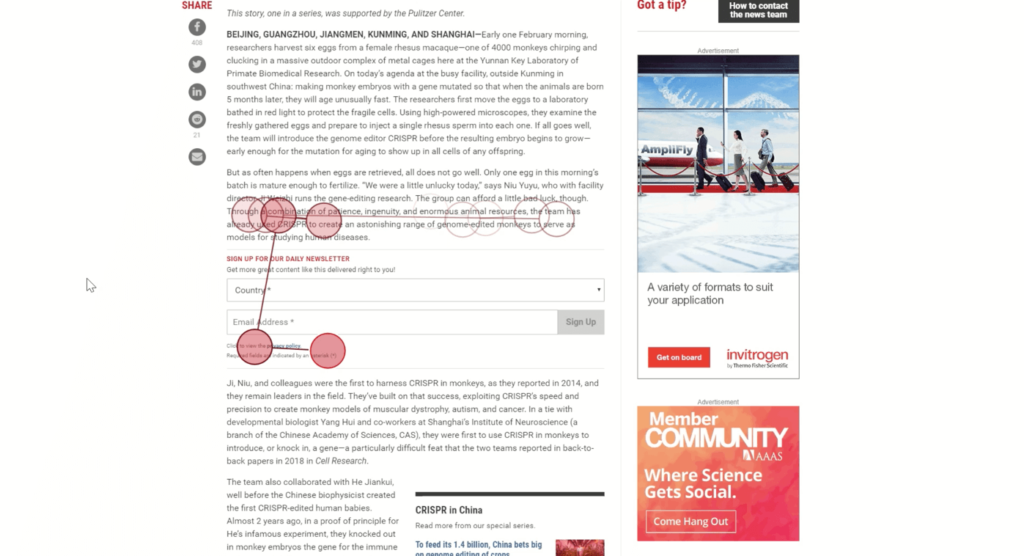
Учасниця відсканувала цю статтю на сайті Science Magazine майже лінійно і повністю, поки не потрапила у вбудовану рекламу. У цей момент її увагу різко впало.
Що не змінилося?
Тенденція до сканування.
Люди досі в основному сканують, а не читають. Читання всього тексту на сторінці все ще вкрай рідко. Навіть коли користувачі сканують контент цілком, вони ніколи не роблять це абсолютно лінійно.
Вони як і раніше бігають по сторінках, пропускають певний контент, повертаються назад, щоб відсканувати пропущене, і повторно сканують вже відсканований контент.
Хоча легке сканування є основним методом, використовуваним для обробки інформації в Інтернеті, кількість часу, який кожен окремий користувач готовий витратити на читання, залежить від чотирьох чинників:
- Рівень мотивації: наскільки важлива ця інформація для користувача?
- Тип завдання: шукає користувач конкретний факт, переглядає нову або цікаву інформацію або досліджує тему?
- Рівень фокуса: наскільки сфокусований (або не сфокусований) користувач на поставленому завданню?
- Особисті характеристики: проявляє ця людина схильність до сканування і чи має він тенденцію до сканування навіть в умовах високої мотивації? Або вона дуже орієнтована на деталі в своєму загальному підході до читання онлайн?
Як і в 2006 році, творці контенту повинні прийняти цей факт: люди навряд чи прочитають ваш контент повністю або лінійно. Вони просто хочуть вибрати інформацію, яка найбільш відповідає їх поточним потребам.
Ми можемо розробити контент, який підтримує сканування:
- Використання чітких помітних заголовків і підзаголовків для поділу розділів контенту і написів, щоб люди могли сканувати, щоб знайти тільки те, що їм найбільше цікаво.
- Зручне розміщення інформації. Іншими словами, «фронтальна завантаження» в структурі нашого контенту, а також короткий зміст і засланнях, щоб люди могли швидко зрозуміти повідомлення під час сканування.
- Використання методів форматування, таких як марковані списки і жирний текст, щоб око могло зосередитися на найбільш важливої інформації.
- Використання простого мови, щоб зміст був коротким і ясним.
Більшість моделей погляду.
Майже всі моделі погляду, що спостерігалися в 2006 році, були присутні в нашому дослідженні 2019 року:
- F-патерн;
- Листковий пиріг;
- Плямистий візерунок;
- Зразок прихильності;
- Вичерпний огляд;
- Обхідний патерн;
- Зигзагоподібний візерунок;
- Послідовний зразок;
- Кохання з першого погляду.
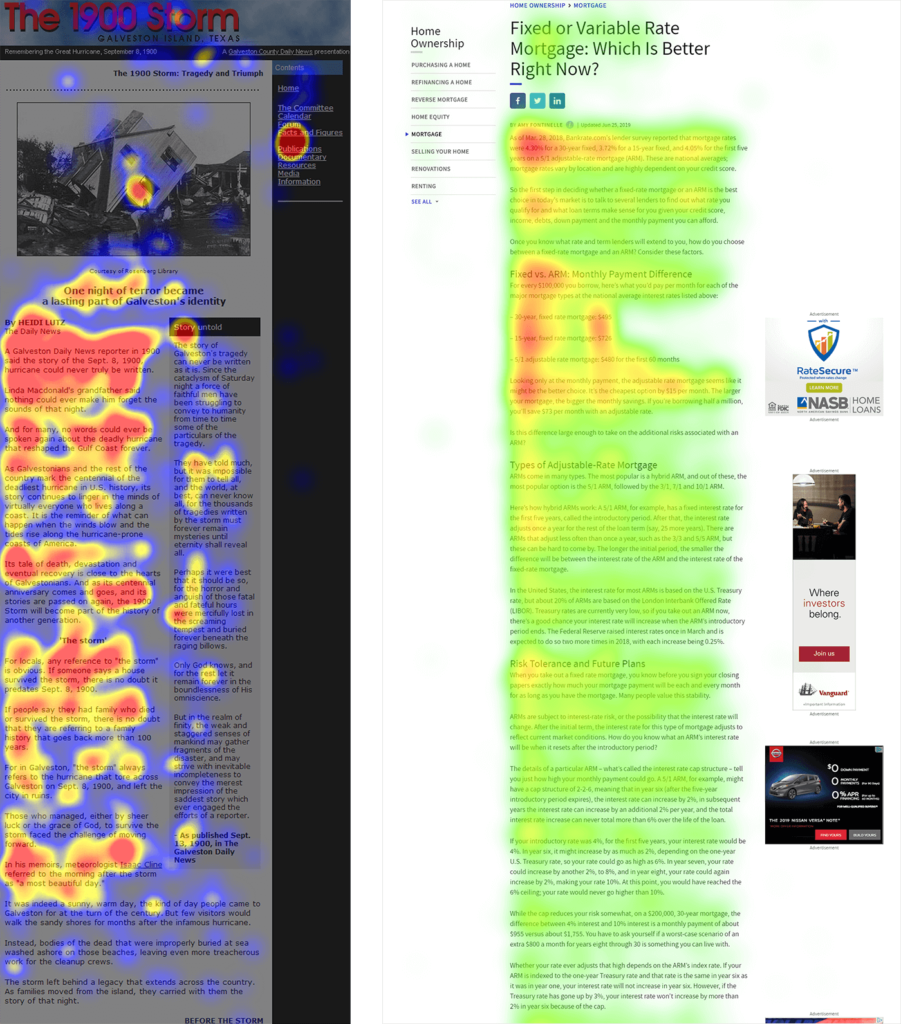
Зліва: один з наших найбільш ранніх прикладів F-патерну, виявлений на початку 2000-х років на 1900storm.com. Справа: недавній екземпляр F-патерну на Investopedia.com.
Керівні принципи, засновані на поведінці людини постійні. Наші оригінальні висновки були засновані на розумінні поведінки людей, що шукають інформацію.
Повний звіт «Як люди читають онлайн» містить:
- Глибокі пояснення і аналіз для всіх моделей погляду і поведінки, згаданих тут.
- Більше 340 ілюстрацій, візуалізація даних погляду і скріншоти з досліджень, 90% з яких є новими для другого видання.
- Актуальні відео-кліпи повторного перегляду сесій трекінгу.
В результаті незважаючи на те, що дизайн за останні два десятиліття змінився, поведінка при читанні в інтернеті за своєю суттю залишається практично однаковим. Технології швидко змінюються, а люди ні.
У всякому разі, ми просто спостерігали нову поведінку, яке розвинулося у відповідь на зміни дизайну. Наприклад, шаблон пинбола. Але всі вони є симптомом більш глибокої істини: люди не хочуть витрачати час або зусилля онлайн.
Поки ми розробляємо контент, який визнає цю реальність і допомагає скеровувати людей лише на ту інформацію, яку вони хочуть, ми будемо на правильному шляху.
За матеріалами сайту: nngroup.com.
✔️ Що таке SERP?
Це сторінка, запропонована пошуковою видачею у відповідь на запит користувача.
✔️ Що таке лінійне читання?
Це читання кожної букви, слова і рядки в тексті.
✔️ Я правильно зрозуміла, сканування - це перегляд матеріалу цілому для пошуку потрібної інформації?
Так, саме так.
✔️ Що таке Baidu?
Це китайська пошукова система для роботи в Інтернеті.
✔️ Як користувачі можуть читати онлайн?
Люди рідко читають веб-сторінки слово в слово; замість цього вони переглядають сторінку, вибираючи окремі слова і пропозиції.
✔️ Як мало читають користувачі?
Переважна більшість користувачів прочитають близько 20% тексту на середньої сторінці.
✔️ Чому люди сканують веб-сайти?
Його користувачі не читають веб-сайти так, як читають інші матеріали; вони сканують, щоб швидко знайти інформацію, яка їм найбільше підходить.


